
Articles
Empowering engineers with everything they need to build, monitor, and scale real-time data pipelines with confidence.

Melbourne Kafka x Flink July Meetup Recap: Real-time Data Hosted by Factor House & Confluent
From structuring data streams to spinning up full pipelines locally, our latest Kafka x Flink meetup in Melbourne was packed with hands-on demos and real-time insights. Catch the highlights and what's next.
On July 31st, we welcomed the Melbourne data streaming community to our Factor House HQ in Northcote for an evening of real-time insights, local dev tools, and excellent company, cohosted with our friends at Confluent.
The event, From Real-Time Data to Insights & Local Development with Kafka and Flink, was packed with engineers, data practitioners, and curious minds looking to deepen their knowledge of stream processing and hands-on development workflows.
Pizza, drinks, and chatter kicked things off, and the vibes didn't disappoint. The crowd was buzzing with conversation, from real-time architectures to favorite CLI tools.
Talks That Delivered
Olena Kutsenko, Staff Developer Advocate at Confluent
Olena Kutsenko, Staff Developer Advocate at Confluent, took the stage first with The Art of Structuring Real-time Data Streams into Actionable Insights. Her talk offered a compelling walkthrough of the Kafka–Flink–Iceberg stack, showing how to tame messy real-time data and prepare it for analytics and AI. Attendees praised her clarity and technical depth:
“Olena managed to communicate her ideas in a way that was comprehensible to non-technical people, whilst still articulating the value for more experienced attendees.”
Jaehyeon Kim, Developer Experience Engineer at Factor House
Read Jae's blog post about Factor House Local & Labs
Next up, Jaehyeon Kim, Developer Experience Engineer at Factor House, gave a tour of Hands-On Local Development: Kafka, Flink, Docker, and more. Jae introduced Factor House Labs — a collection of open-source Docker environments designed to get engineers experimenting with modern data platforms fast.
“Jae’s passion for the product was infectious. His demo showed just how easy it is to spin up a full end-to-end data pipeline locally.”

Community, Connection, and What’s Next
Beyond the talks, a big highlight was the crowd itself. We saw first-timers, veterans, and everyone in between sharing ideas and chatting about use cases.
This meetup also marked the launch of the Factor House Community on Slack, a space to keep the conversation going, swap tips, and collaborate on all things real-time.

Next Stop: Sydney!
Couldn’t make it to Melbourne? This meetup will happen again in Sydney on September 16. Sydney Apache Kafka x Flink Meetup
Stay Connected
Want to hear about future events, tools, and hands-on learning experiences?

Heading 1
Heading 2
Heading 3
Heading 4
Heading 5
Heading 6
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Block quote
Ordered list
- Item 1
- Item 2
- Item 3
Unordered list
- Item A
- Item B
- Item C
Bold text
Emphasis
Superscript
Subscript

Join the conversation: Factor House launches open Slack for the real-time data community
Factor House has opened a public Slack for anyone working with streaming data, from seasoned engineers to newcomers exploring real-time systems. This space offers faster peer-to-peer support, open discussion across the ecosystem, and a friendly on-ramp for those just getting started.
Come and #say-hi
We've opened the Factor House Community Slack: a public space for anyone working in the streaming data world. Whether you're a seasoned data engineer, exploring streaming technologies for the first time, or just curious about real-time systems, this is your place to connect, learn, and share.
Join the Factor House Community Slack →
Our community isn’t just a chatroom, it’s part of building the collective intelligence that will shape the future of data in motion. We’re connecting the engineers, operators, and curious learners who will define what streaming infrastructure looks like in the AI era.
What changed (and why)
For years, our team, customers, and broader community were all in one busy workspace. It was a good start, but as our products and community grew, so did the noise. Support conversations were mixed with team chatter and community discussions, leaving newcomers unsure of where to begin.
We've split into two focused spaces:
- Factor House Community (public) - Where the magic happens
- Private workspace - For our team and client engagements
To our existing customers: thank you for your patience during this transition. Your feedback helps us build something better, and we're grateful for engineers who push us to improve.
Why join?
- Current users: Get faster answers from real humans who've solved similar problems. Our team is active daily on weekdays (Australian timezone), and we're building a community that helps each other.
- Newcomers: This is your friendly on-ramp to the data streaming world. Ask the "obvious" questions - we love helping engineers grow.
- Ecosystem: We're vendor-neutral and open-source friendly. Discuss any tools, share knowledge, and make announcements. The more diverse perspectives, the better.
Here’s where you’ll find us (and each other):
- #say-hi: introduce yourself to the community
- #getting-started: new to Kpow or Flex? Begin your journey here
- #ask-anything: all questions welcome, big or small
- #product-kpow & #product-flex: features, releases, and best practices for FH tooling
- #house-party: off-topic bants, memes, and pet pics
Our team is in the mix too. You’ll spot us by the Factor House logo in our status.
Community Guidelines
We want this community to reflect the best parts of engineering culture: openness, generosity, and curiosity. It’s not just about solving problems faster, it’s about building a place where people can do their best work together.
This is a friendly, moderated space. We ask everyone to be respectful and inclusive (read our code of conduct). Keep conversations in public channels wherever possible so everyone benefits.
For our customers: use your dedicated support channels or support@factorhouse.io for SLA-bound requests and bug reports. The community Slack is best-effort support.
Ready to Join?
This Slack is the seed of a wider ecosystem. It's a place where engineers share knowledge, swap stories, and push the boundaries of what’s possible with streaming data. It’s the beginning of a developer community that will grow alongside our platform.
This community will become what we make of it. We're hoping for technical discussions, mutual help, and the kind of engineering conversations that make your day better.
Join the Factor House Community Slack →
Come #say-hi and tell us what you're working on. We're genuinely curious about what keeps data engineers busy.

Heading 1
Heading 2
Heading 3
Heading 4
Heading 5
Heading 6
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Block quote
Ordered list
- Item 1
- Item 2
- Item 3
Unordered list
- Item A
- Item B
- Item C
Bold text
Emphasis
Superscript
Subscript
.png)
Introduction to Factor House Local
Jumpstart your journey into modern data engineering with Factor House Local. Explore pre-configured Docker environments for Kafka, Flink, Spark, and Iceberg, enhanced with enterprise-grade tools like Kpow and Flex. Our hands-on labs guide you step-by-step, from building your first Kafka client to creating a complete data lakehouse and real-time analytics system. It's the fastest way to learn, prototype, and build sophisticated data platforms.
Factor House Local is a collection of pre-configured Docker Compose environments that demonstrate modern data platform architectures. Each setup is purpose-built around a specific use case and incorporates widely adopted technologies such as Kafka, Flink, Spark, Iceberg, and Pinot. These environments are further enhanced by enterprise-grade tools from Factor House: Kpow, for Kafka management and control, and Flex, for seamless integration with Flink.

Data Stack
Kafka Development & Monitoring with Kpow
This stack provides a comprehensive, locally deployable Apache Kafka environment designed for robust development, testing, and operations. It utilizes Confluent Platform components, featuring a high-availability 3-node Kafka cluster, Zookeeper, Schema Registry for data governance, and Kafka Connect for data integration.
The centerpiece of the stack is Kpow (by Factorhouse), an enterprise-grade management and observability toolkit. Kpow offers a powerful web UI that provides deep visibility into brokers, topics, and consumer groups. Key features include real-time monitoring, advanced data inspection using kJQ (allowing complex queries across various data formats like Avro and Protobuf), and management of Schema Registry and Kafka Connect. Kpow also adds critical enterprise features such as Role-Based Access Control (RBAC), data masking/redaction for sensitive information, and audit logging.
Ideal For: Building and testing microservices, managing data integration pipelines, troubleshooting Kafka issues, and enforcing data governance in event-driven architectures.
Unified Analytics Platform (Flex, Flink, Spark, Iceberg & Hive Metastore)
This architecture establishes a modern Data Lakehouse that seamlessly integrates real-time stream processing and large-scale batch analytics. It eliminates data silos by allowing both Apache Flink (for streaming) and Apache Spark (for batch) to operate on the same data.
The foundation is built on Apache Iceberg tables stored in MinIO (S3-compatible storage), providing ACID transactions and schema evolution. A Hive Metastore, backed by PostgreSQL, acts as the unified catalog for both Flink and Spark. The PostgreSQL instance is also configured for Change Data Capture (CDC), enabling real-time synchronization from transactional databases into the lakehouse.
The stack includes Flex (by Factorhouse), an enterprise toolkit for managing and monitoring Apache Flink, offering enhanced security, multi-tenancy, and deep insights into Flink jobs. A Flink SQL Gateway is also included for interactive queries on live data streams.
Ideal For: Unified batch and stream analytics, real-time ETL, CDC pipelines from operational databases, fraud detection, and interactive self-service analytics on a single source of truth.
Apache Pinot Real-Time OLAP Cluster
This stack deploys the core components of Apache Pinot, a distributed OLAP (Online Analytical Processing) datastore specifically engineered for ultra-low-latency analytics at high throughput. Pinot is designed to ingest data from both batch sources (like S3) and streaming sources (like Kafka) and serve analytical queries with millisecond response times.
Ideal For: Powering real-time, interactive dashboards; user-facing analytics embedded within applications (where immediate feedback is crucial); anomaly detection; and rapid A/B testing analysis.
Centralized Observability & Data Lineage
This stack provides a complete solution for understanding both system health and data provenance. It combines Marquez, the reference implementation of the OpenLineage standard, with the industry-standard monitoring suite of Prometheus, Grafana, and Alertmanager.
At its core, OpenLineage enables automated data lineage tracking for Kafka, Flink, and Spark workloads by providing a standardized API for emitting metadata about jobs and datasets. Marquez consumes these events to build a living, interactive map of your data ecosystem. This allows you to trace how datasets are created and consumed, making it invaluable for impact analysis and debugging. The Prometheus stack complements this by collecting time-series metrics from all applications, visualizing them in Grafana dashboards, and using Alertmanager to send proactive notifications about potential system issues.
Ideal For: Tracking data provenance, performing root cause analysis for data quality issues, monitoring the performance of the entire data platform, and providing a unified view of both data lineage and system health.
Factor House Local Labs
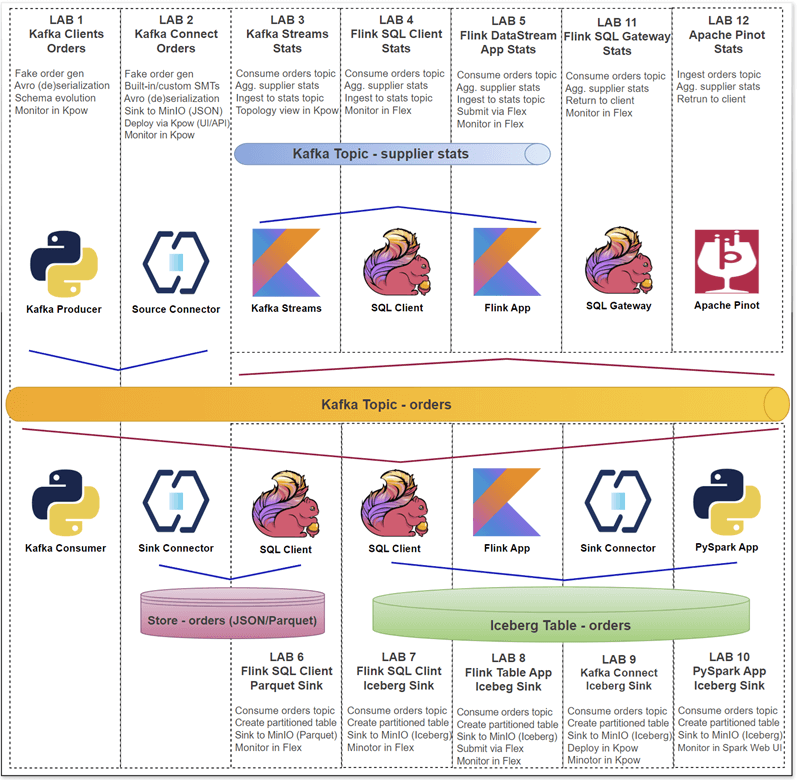
The Factor House Local labs are a series of 12 hands-on tutorials designed to guide developers through building real-time data pipelines and analytics systems. The labs use a common dataset of orders from a Kafka topic to demonstrate a complete, end-to-end workflow, from data ingestion to real-time analytics.
The labs are organized around a few key themes:
💧 Lab 1 - Streaming with Confidence:
- Learn to produce and consume Avro data using Schema Registry. This lab helps you ensure data integrity and build robust, schema-aware Kafka streams.
🔗 Lab 2 - Building Data Pipelines with Kafka Connect:
- Discover the power of Kafka Connect! This lab shows you how to stream data from sources to sinks (e.g., databases, files) efficiently, often without writing a single line of code.
🧠 Labs 3, 4, 5 - From Events to Insights:
- Unlock the potential of your event streams! Dive into building real-time analytics applications using powerful stream processing techniques. You'll work on transforming raw data into actionable intelligence.
🏞️ Labs 6, 7, 8, 9, 10 - Streaming to the Data Lake:
- Build modern data lake foundations. These labs guide you through ingesting Kafka data into highly efficient and queryable formats like Parquet and Apache Iceberg, setting the stage for powerful batch and ad-hoc analytics.
💡 Labs 11, 12 - Bringing Real-Time Analytics to Life:
- See your data in motion! You'll construct reactive client applications and dashboards that respond to live data streams, providing immediate insights and visualizations.
Overall, the labs provide a practical, production-inspired journey, showing how to leverage Kafka, Flink, Spark, Iceberg, and Pinot together to build sophisticated, real-time data platforms.
Conclusion
Factor House Local is more than just a collection of Docker containers; it represents a holistic learning and development ecosystem for modern data engineering.
The pre-configured stacks serve as the ready-to-use "what," providing the foundational architecture for today's data platforms. The hands-on labs provide the practical "how," guiding users step-by-step through building real-world data pipelines that solve concrete problems.
By bridging the gap between event streaming (Kafka), large-scale processing (Flink, Spark), modern data storage (Iceberg), and low-latency analytics (Pinot), Factor House Local demystifies the complexity of building integrated data systems. Furthermore, the inclusion of enterprise-grade tools like Kpow and Flex demonstrates how to operate these systems with the observability, control, and security required for production environments.
Whether you are a developer looking to learn new technologies, an architect prototyping a new design, or a team building the foundation for your next data product, Factor House Local provides the ideal starting point to accelerate your journey.
Heading 1
Heading 2
Heading 3
Heading 4
Heading 5
Heading 6
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Block quote
Ordered list
- Item 1
- Item 2
- Item 3
Unordered list
- Item A
- Item B
- Item C
Bold text
Emphasis
Superscript
Subscript
.webp)
Improvements to Data Inspect in Kpow 94.3
Kpow's 94.3 release is here, transforming how you work with Kafka. Instantly query topics using plain English with our new AI-powered filtering, automatically decode any message format without manual setup, and leverage powerful new enhancements to our kJQ language. This update makes inspecting Kafka data more intuitive and powerful than ever before.
Overview
Kpow's Data Inspect feature has always been a cornerstone for developers working with Apache Kafka, offering a powerful way to query and understand topic data, as introduced in our earlier guide on how to query a Kafka topic.
The 94.3 release dramatically enhances this experience by introducing a suite of intelligent and user-friendly upgrades. This release focuses on making data inspection more accessible for all users while adding even more power for advanced use cases. The key highlights include AI-powered message filtering, which allows you to query Kafka using plain English; automatic deserialization, which removes the guesswork when dealing with unknown data formats; and significant enhancements to the kJQ language itself, providing more flexible and powerful filtering capabilities.
About Factor House
Factor House is a leader in real-time data tooling, empowering engineers with innovative solutions for Apache Kafka® and Apache Flink®.
Our flagship product, Kpow for Apache Kafka, is the market-leading enterprise solution for Kafka management and monitoring.
Explore our live multi-cluster demo environment or grab a free Community license and dive into streaming tech on your laptop with Factor House Local.
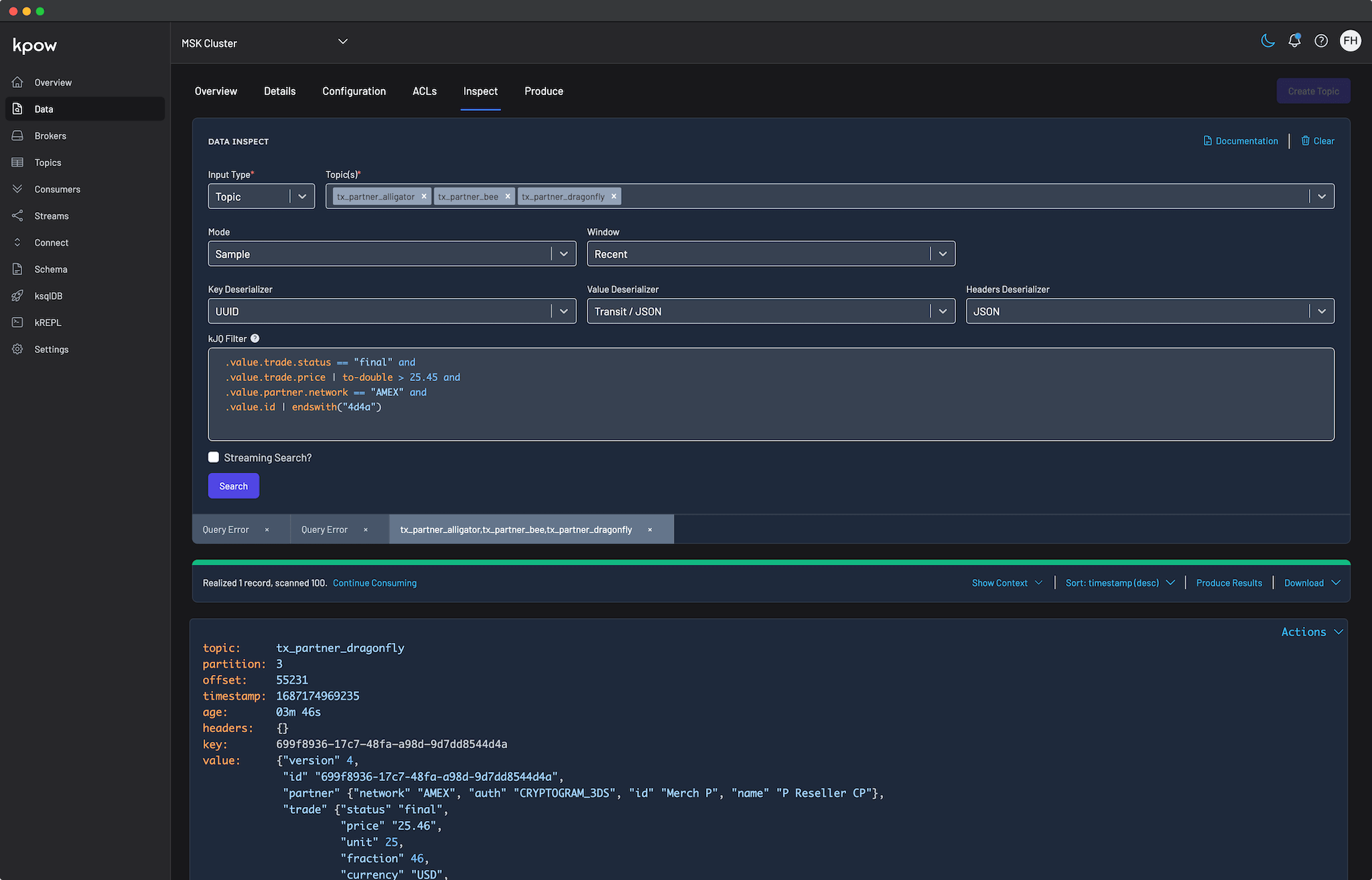
AI-Powered Message Filtering
Kpow now supports the integration of external AI models to enhance its capabilities, most notably through its "bring your own" (BYO) AI model functionality. This allows you to connect Kpow with various AI providers to power features within the platform.
AI Model Configuration
You have the flexibility to configure one or more AI model providers. Within your Kpow user preferences, you can then set a default model for all AI-assisted tasks. Configuration is managed through environment variables and is supported for the following providers:
| Provider |
Environment Variable
|
Description | Default |
Example
|
|---|---|---|---|---|
| OpenAI |
'OPENAI_API_KEY'
|
Your OpenAI API key | (required) | 'XXXX' |
|
'OPENAI_MODEL'
|
Model ID to use | 'gpt-4o-mini' | 'o3-mini' | |
| Anthropic |
'ANTHROPIC_API_KEY'
|
Your Anthropic API key | (required) | 'XXXX' |
|
'ANTHROPIC_MODEL'
|
Model ID to use | 'claude-3-7-sonnet-20250219' | 'claude-opus-4-20250514' | |
| Ollama |
'OLLAMA_MODEL'
|
Model ID to use (must support tools) | - | 'llama3.1:8b' |
|
OLLAMA_URL
|
URL of the Ollama model server | 'http://localhost:11434' |
https://prod.ollama.mycorp.io
|
If you need support for a different AI provider, you can contact the Factor House support team.
Enhanced AI Features
The primary AI-driven feature is the kJQ filter generation. This powerful tool enables you to query Kafka topics using natural language. Instead of writing complex kJQ expressions, you can simply describe the data you're looking for in plain English.
Here's how it works:
- Natural Language Processing: The system converts your conversational prompts (e.g., "show me all orders over $100 from the last hour") into precise kJQ filter expressions.
- Schema-Awareness: To improve accuracy, the AI can optionally use the schemas of your Kafka topics to understand field names, data types, and the overall structure of your data.
- Built-in Validation: Every filter generated by the AI is automatically checked against Kpow's kJQ engine to ensure it is syntactically correct before you run it.
This feature is accessible from the Data Inspect view for any topic. After the AI generates a filter, you have the option to execute it immediately, modify it for more specific needs, or save it for later use. For best results, it is recommended to provide specific and actionable descriptions in your natural language queries.
It is important to be mindful that AI-generated filters are probabilistic and may not always be perfect. Additionally, when using cloud-based AI providers, your data will be processed by them, so for sensitive information, using local models via Ollama or enterprise-grade AI services with strong privacy guarantees is recommended.
For more details, see the AI Models documentation.

Automatic Deserialization
Kpow simplifies data inspection with its "Auto SerDes" feature. In the Data Inspect view, you can select "Auto" as the deserializer, and Kpow will analyze the raw data to determine its format (like JSON, Avro, etc.) and decode it for you. This is especially useful in several scenarios, including:
- When you are exploring unfamiliar topics for the first time.
- While working with topics that may contain mixed or inconsistent data formats.
- When debugging serialization problems across different environments.
- For onboarding new team members who need to get up to speed on topic data quickly.
To make these findings permanent, you can enable the Topic SerDes Observation job by setting INFER_TOPIC_SERDES=true. When active, this job saves the automatically detected deserializer settings and any associated schema IDs, making them visible and persistent in the Kpow UI for future reference.

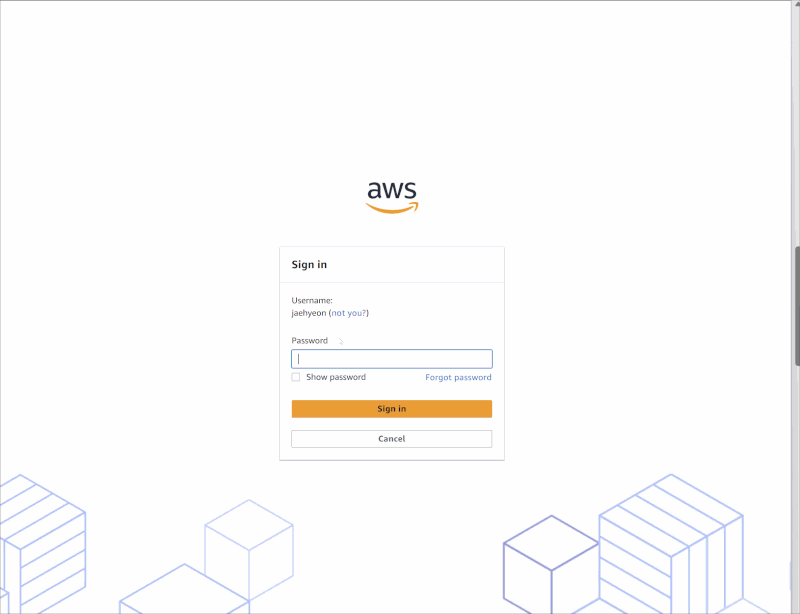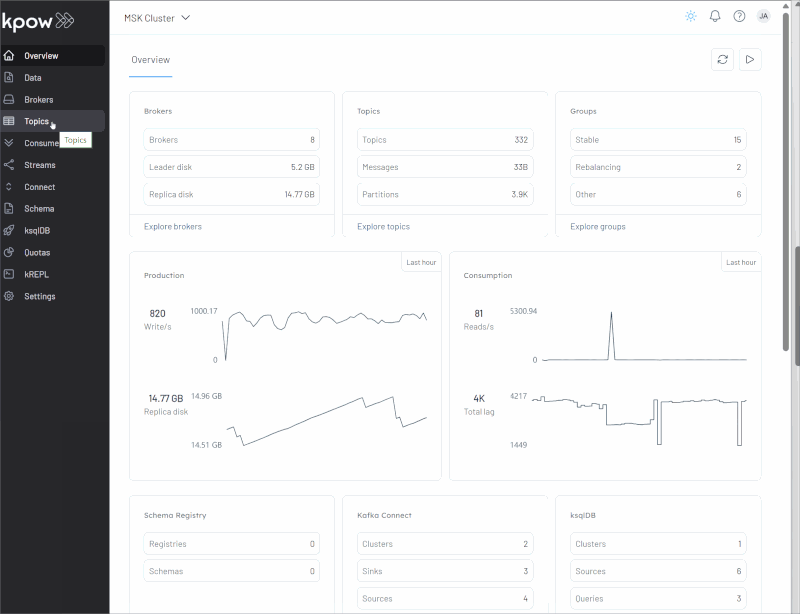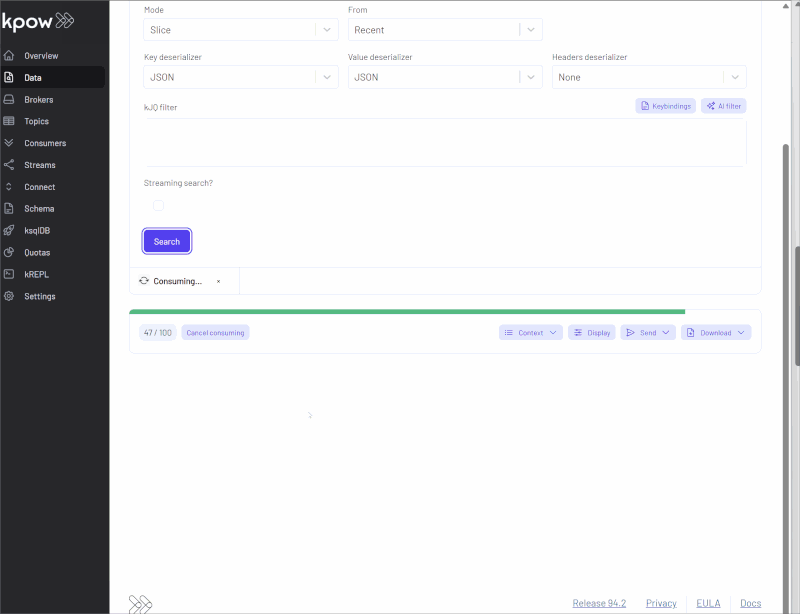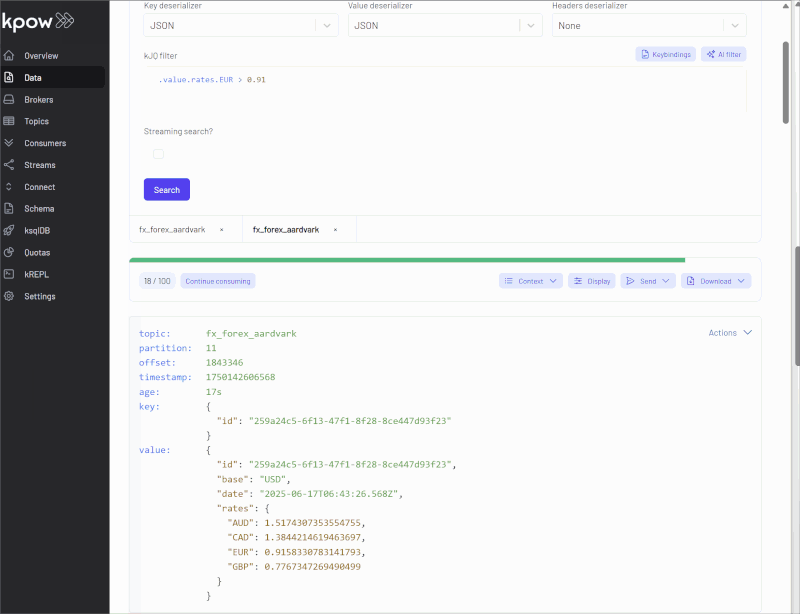
kJQ Language Enhancements
In response to our customers' evolving filtering needs, we've significantly improved the kJQ language to make Kafka record filtering more powerful and flexible. Check out the updated kJQ filters documentation for full details.
Below are some highlights of the improvements:
Chained alternatives
Selects the first non-null email address and checks if it ends with ".com":
.value.primary_email // .value.secondary_email // .value.contact_email | endswith(".com")String/Array slices
Matches where the first 3 characters of transaction_id equal TXN:
.value.transaction_id[0:3] == "TXN"For example, { "transaction_id": "TXN12345" } matches, while { "transaction_id": "ORD12345" } does not
UUID type support
kJQ supports UUID types out of the box, including the UUID deserializer, AVRO + logical types, or Transit / JSON and EDN deserializers that have richer data types.
To compare against literal UUID strings, prefix them with #uuid to coerce into a UUID:
.key == #uuid "fc1ba6a8-6d77-46a0-b9cf-277b6d355fa6"
Conclusion
The 94.3 release marks a significant leap forward for data exploration in Kpow. By integrating AI for natural language queries, automating the complexities of deserialization, and enriching the kJQ language with advanced functions, Kpow now caters to an even broader range of users. These updates streamline workflows for everyone, from new team members who can now inspect topics without prior knowledge of data formats, to seasoned engineers who can craft more sophisticated and precise queries than ever before. This release reaffirms our commitment to simplifying the complexities of Apache Kafka and empowering teams to unlock the full potential of their data with ease and efficiency.
Heading 1
Heading 2
Heading 3
Heading 4
Heading 5
Heading 6
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Block quote
Ordered list
- Item 1
- Item 2
- Item 3
Unordered list
- Item A
- Item B
- Item C
Bold text
Emphasis
Superscript
Subscript

Ensuring Your Data Streaming Stack Is Ready for the EU Data Act
The EU Data Act takes effect in September 2025, introducing major implications for teams running Kafka. This article explores what the Act means for data streaming engineers, and how Kpow can help ensure compliance — from user data access to audit logging and secure interoperability.
Introduction: What’s Changing?
The EU Data Act, effective as of September 12, 2025, introduces new requirements for data access, sharing, and interoperability across the European Union's single market. For engineers managing data streaming platforms like Apache Kafka, this means re-evaluating how your stack handles user data, security, provider switching, and compliance with both the Data Act and GDPR.
What Does the EU Data Act Mean for Data Streaming?
At its core, the Data Act requires that users of connected products and services have access to their raw usage data and metadata. This means that streaming platforms processing such data need to enable seamless and secure access and sharing capabilities. Additionally, the Act outlines rules for business-to-business and business-to-government data sharing, while safeguarding trade secrets and ensuring the security of data.
Key highlights of the Act
Why These Changes Matter for Kafka Engineers
Kafka is at the heart of many modern data streaming architectures, making it critical to align Kafka operations with these new legal requirements. Engineers must ensure:
- Data streams can be accessed and shared securely and transparently.
- Systems support interoperability to facilitate provider switching without data loss or downtime.
- Access controls and auditing are in place to protect sensitive data and demonstrate compliance.
- Data subject rights under GDPR, such as access, correction, and deletion, can be fulfilled efficiently.
How Kpow Supports Compliance and Operational Excellence
At Factor House, we designed Kpow with these challenges in mind. As an enterprise-native company, our flagship solution Kpow is a comprehensive Kafka management and monitoring platform that empowers engineers to meet the demands of the new EU data landscape. Right out of the box, Kpow enables engineers to meet stringent EU Data Act requirements with ease.
| EU Data Act |
Kpow's fulfilment out-of-the-box
|
|---|---|
| Data Access and Portability: Data processing services must provide users and authorized third parties access to product and service data in accessible, interoperable formats and to support seamless switching between providers. |
Kpow connects directly to Kafka clusters using standard client configurations, enabling
engineers to expose and manage streaming data effectively, supporting data access requests and
portability without vendor lock-in or switching charges.
|
| Transparency and Jurisdictional Information: Mandated transparency about the jurisdiction of ICT infrastructure and the technical, organizational, and contractual safeguards against unlawful international governmental access to non-personal data. |
Kpow stores all monitoring data locally within Kafka clusters, minimizing data exposure and
supporting data sovereignty.
|
| Security and Access Controls: Protect trade secrets and personal data, and comply with GDPR when personal data is involved. |
Kpow integrates with enterprise-grade authentication providers (OAuth2, OpenID, SAML, LDAP) and
implements configurable Role-Based Access Control (RBAC), ensuring that only authorized users
can access sensitive data streams. Kpow allows configurable redaction of data inspection results
through its data policies, providing enhanced protection against the exposure of sensitive
information.
|
| Auditability and Monitoring: Data sharing and security require an auditable trail of who accessed what data and when. |
Kpow provides rich telemetry, consumer group insights, and audit logging capabilities, enabling
organizations to monitor data access and usage.
|
| Service Switching and Interoperability: Ensure customers can migrate data streaming workloads smoothly without disruption or additional costs. |
Kpow enables multi-cluster management through standard Kafka client configurations, allowing
seamless connection, monitoring, and migration across multiple Kafka clusters and environments
without vendor lock-in or proprietary dependencies.
|
| Internal Procedures and Legal Compliance Support: Protect trade secrets and other sensitive data while enabling lawful data sharing without unnecessary obstruction. |
By providing detailed visibility and control over Kafka data streams, Kpow helps organizations
implement internal procedures to respond promptly to data access requests, identify trade
secrets, and apply necessary protective measures.
|
Practical Steps for Engineers
- Review your current Kafka stack: Ensure configurations support data access, portability, and interoperability.
- Implement robust authentication and RBAC: Protect sensitive streams and support GDPR compliance.
- Enable detailed audit logging: Prepare for regulatory audits and internal monitoring.
- Test provider switching: Validate that you can migrate workloads without disruption or extra costs.
- Stay updated: Monitor regulatory updates and best practices for ongoing compliance.
Access "Turnkey" Compliance with Kpow
Kpow’s secure, transparent, and flexible Kafka management capabilities align with the EU Data Act’s requirements, enabling controlled data access, robust security, local data storage, auditability, and interoperability. This makes it an effective tool for data streaming engineers and organizations aiming to comply with the EU’s new data sharing and protection rules starting September 2025.
Future-Proof Your Kafka Streaming
The EU Data Act is reshaping how data streaming services operate in Europe. Ensuring your Kafka infrastructure is compliant and resilient is no longer optional—it’s essential.
To help you navigate this transition, Factor House offers a free 30-day fully-featured trial license of Kpow.
Experience firsthand how Kpow’s secure, transparent, and flexible Kafka management capabilities can simplify compliance and enhance your streaming operations. Start your free trial of Kpow today.
Sources (and further information)
Heading 1
Heading 2
Heading 3
Heading 4
Heading 5
Heading 6
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Block quote
Ordered list
- Item 1
- Item 2
- Item 3
Unordered list
- Item A
- Item B
- Item C
Bold text
Emphasis
Superscript
Subscript

Beyond Kafka: Sharp Signals from Current London 2025
The real-time ecosystem has outgrown Kafka alone. At Current London 2025, the transition from Kafka Summit was more than a name change — it marked a shift toward streaming-first AI, system-level control, and production-ready Flink. Here's what Factor House saw and learned on the ground.
The transition from Kafka Summit to Current is now complete, with this year's London conference now rebranded to match Confluent’s US and India events and providing a strong indicator that the real-time ecosystem now extends far beyond Apache Kafka. With more than 2,200 attendees, in-depth technical presentations, and countless exhibitor hall discussions, it is evident that real-time streaming is here to stay and the ecosystem is evolving quickly, branching out into AI-native systems, multi-technology stacks, and production-grade stream processing.
What We Saw
For the third consecutive year, Factor House was on the ground in London as a Silver Sponsor, running product demos, meeting clients, and, more importantly, learning about the needs of engineers managing complex deployments, platform teams integrating Flink and Kafka, and architects exploring AI built on live data.
While the Kafka Summit name has been replaced, Kafka remains a foundational technology. However, attention is shifting to system-level control, end-to-end observability, and tools that reduce operational friction without sacrificing power. We’re focused on that space with Kpow for Kafka, Flex for Flink, and, soon, the Factor Platform.
Key Signals
- AI Is Going Event-Driven - But Engineers Remain Cautious
- Streaming-first AI was a recurring theme at Current. Sessions like "Flink Jobs as Agents" (Airy Inc.) explored how AI agents can interact with a live state, reacting in real time rather than relying on stale snapshots.
- But several engineers we spoke to flagged concerns.
- While Kafka and Flink provide the backbone, durable, deterministic, and observable, the idea of introducing autonomous agents into critical pipelines raised eyebrows. There’s excitement, yes, but also scepticism around operational safety, debuggability, and unintended consequences. As one engineer put it:
- “If an LLM is making decisions in my pipeline, I want to know what it saw, why it acted, and how to stop it fast.”
- Visibility and control are not optional; they’re the line between innovation and outage. AI might be event-driven, but it’s still infrastructure. And infrastructure needs guardrails.
- Production Resilience > Architectural Purity
- Sessions from OpenAI, AWS, and Daimler all emphasized pragmatism. OpenAI’s Changing Engines Mid-Flight offered real lessons on handling Kafka migrations under load. Elegant designs are great, but shipping reliable systems matters most.
- Flink Is Now a First-Class Citizen
- Flink moved from curiosity to cornerstone. Teams from ShareChat, Wix, and Pinterest shared how they reduced latency and costs while simplifying their pipelines. However, Flink remains operationally raw; hence, Flex, our UI and API, is designed to make Flink observable and manageable in real production environments.
Noteworthy Tools
We saw an uptick in focused tools solving specific friction points, some standouts for us:
- ShadowTraffic – Safe, controlled Kafka traffic simulation.
- RisingWave – Real-time SQL queries over Kafka streams.
- Gravitee – Fine-grained Kafka API access control.
- Imply – Sub-second dashboards on live data.
- Snowplow – Clean, structured enrichment pipelines for streaming events.
Where Factor House Fits
As complexity grows and streaming intersects with AI, teams need visibility, safety, and efficiency, not more abstraction. Our upcoming Factor Platform unifies Kpow and Flex into a single control plane for data in motion, enabling teams to manage Kafka and Flink with confidence across clusters, clouds, and regions, and providing a layer of clarity across an organizations complete streaming ecosystem.
If you’d like to learn more about Factor House products book a demo today.
Heading 1
Heading 2
Heading 3
Heading 4
Heading 5
Heading 6
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Block quote
Ordered list
- Item 1
- Item 2
- Item 3
Unordered list
- Item A
- Item B
- Item C
Bold text
Emphasis
Superscript
Subscript
Join the Factor Community
We’re building more than products, we’re building a community. Whether you're getting started or pushing the limits of what's possible with Kafka and Flink, we invite you to connect, share, and learn with others.


